Abschlussarbeiten im Media Lab | 01.09.2024
Data-Driven-Storytelling 2.0: Personalisierte Datenanimationen

Klimakrise: Zu komplex und schwer greifbar? Personalisierte Datenanimationen im digitalen Journalismus machen solche Themen verständlicher. Ein Prototyp zeigt, wie maßgeschneiderte Visualisierungen und Interaktivität die Nutzer:innen stärker einbinden.
In der heutigen digitalen Ära stehen Journalist:innen vor neuen Herausforderungen und Möglichkeiten, ihre Geschichten online zu erzählen. Eine Möglichkeit sind visuelle Datengeschichten und Grafiken. Die New York Times machte es vor knapp zehn Jahren mit ihrer Geschichte Snow Fall vor und viele Medien folgten ihrem Beispiel. Was man dabei jedoch bis heute selten findet, sind Personalisierung und Individualisierung. In meiner Masterarbeit an der Universität Bamberg habe ich mich intensiv mit diesem Thema auseinandergesetzt und eine personalisierte Geschichte durch interaktive datengesteuerte Animationen entworfen.
Mehr Innovation beim Storytelling
Die Kommunikation komplexer Themen ist für Journalist:innen immer wieder eine Herausforderung. Dabei lässt sich oft schon mit einfachen Bildern ein Thema verständlicher erklären. Doch in der heutigen Zeit gibt es noch weit mehr Möglichkeiten, Geschichten zu erzählen: mit interaktiven und datengesteuerten Animationen. Sie stellen Informationen nicht nur dar, sondern machen sie erlebbar und können so die Aufmerksamkeit und das Verständnis der Leser:innen erhöhen.
Die Klimakrise als Use Case
Ein zentrales Anwendungsbeispiel in meiner Arbeit ist die Klimakrise. Durch personalisierte Darstellungen können Nutzer:innen nämlich Informationen über die Krise erhalten, die speziell auf ihre Region oder ihre Interessen zugeschnitten sind und ihnen so helfen, komplexe Zusammenhänge zu begreifen. Beispiele für eine mögliche Visualisierung sind ein extremes Wetterereignis wie Hitze- oder Kältetage, Dürreperioden oder Niederschlagsmengen. Im besten Fall fördert dies nicht nur das Verständnis, sondern auch das Engagement der Leser:innen.
Schlüsselfunktionen eines interaktiven und personalisierten Prototyps
Im Zentrum meiner Arbeit stand die Entwicklung eines Prototyps mit folgenden Schlüsselfunktionen:
- Datenanalyse und -auswahl: Der erste Schritt war die Sammlung und Analyse relevanter Daten. Für das Beispiel der Klimakrise wurden Daten zu extremen Wetterereignissen, Dürreperioden und anderen Klimakennwerten, wie Lufttemperatur oder Niederschlagsmengen, gesammelt und analysiert.
Personalisierung: Der Prototyp schneidet mit Hilfe einer Abfrage von Name und Landkreis die gesammelten Daten individuell auf die Nutzer:innen zu. Das bedeutet, dass Nutzer:innen Datenvisualisierungen erhalten, die spezifisch für ihre Region oder ihre Interessen relevant sind. Der Name wird verwendet, um eine persönliche Ansprache der Nutzer:innen zu ermöglichen.

Die Leser:innen erhalten je nach Region, die sie ausgewählt haben, andere Zuschnitte ihrer Geschichte.
Interaktive Elemente: Der Prototyp enthält interaktive Elemente, die es den Nutzer:innen ermöglichen, aktiv mit den Daten zu interagieren. Dazu gehören klickbare Diagramme und Grafiken, die detaillierte Informationen und weiterführende Erklärungen bieten.
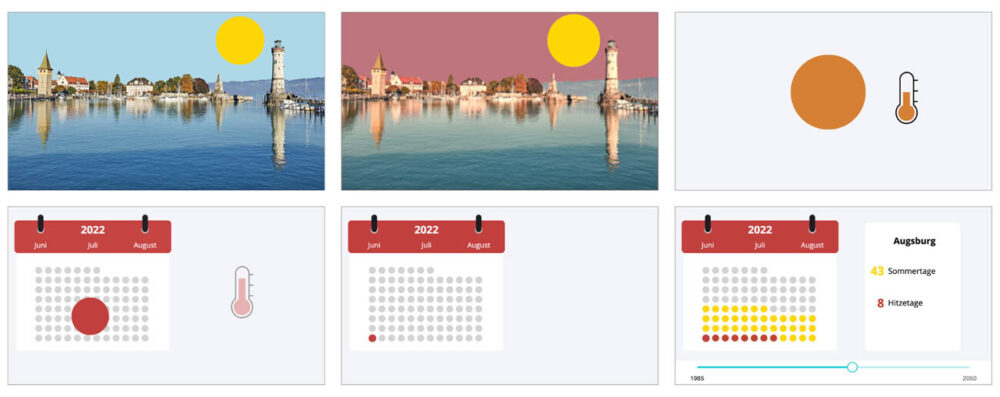
Ein Klick auf die Sonne löst eine Animation aus und die Szene baut Schritt für Schritt die Datenvisualisierung auf. Mit dem Slider am Ende können die Leser:innen die Daten selbst analysieren.
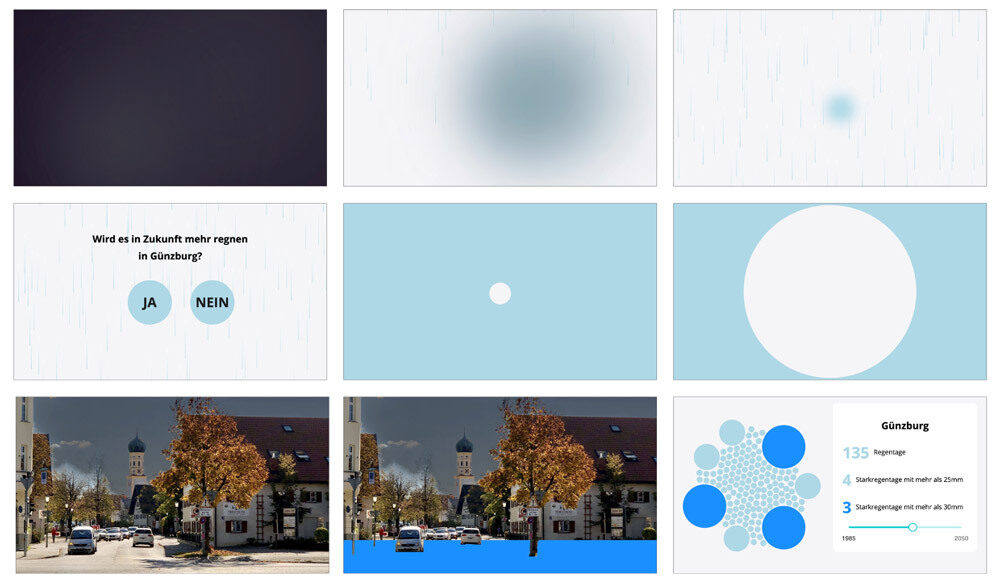
Eine Abfrage involviert die Leser:innen mehr in die Geschichte.
- Narrative Struktur: Um die Daten verständlich und ansprechend zu präsentieren, habe ich eine narrative Struktur entwickelt. Diese Struktur stellt sicher, dass die Daten auf einen logischen und fesselnden Erzählfluss einzahlen
- Sonifikation: Entsprechender Sound unterstützt die Datenvisualisierungen zusätzlich und fügt der Geschichte eine auditive Komponente hinzu. Text-To-Speech macht außerdem eine individuelle Ansprache der User möglich.
Verknüpfen von verschiedenen Web-Technologien
Für die Umsetzung des Prototyps habe ich moderne Web-Technologien wie React, D3.js, Framer, HTML, CSS, Python und Cloud-Technologien verwendet. Insgesamt besteht die Anwendung aus zwei Hauptkomponenten:
- Backend:
Das Backend - entwickelt mit Python - liefert die Daten und stellt sie über einen Cloud-Service effizient verwaltet zur Verfügung. Die Anwendung speichert die Daten im JSON-Format und übermittelt sie dynamisch durch Ajax-Anfragen an das Frontend. Dadurch können die Daten in Echtzeit aktualisiert und in die Visualisierungen geladen werden.
- Frontend:
Das Frontend ist die Oberfläche, die den Nutzer:innen im Browser zur Verfügung steht. Ich habe es mit React und D3.js entwickelt, um eine dynamische und interaktive Benutzeroberfläche zu schaffen. Die Gestaltung und Animation von UI-Komponten/Grafikelementen läuft über Framer. Das Frontend kommuniziert sowohl mit dem Backend als auch mit einer Schnittstelle zu Elevenlabs, um dynamisch die Sounddateien zu laden und abzuspielen.
Die technische Umsetzung des Prototyps war äußerst zeitintensiv, da die gesamte Geschichte in einzelne Komponenten zerlegt und gestaltet werden musste. Zudem erforderte jede Animation und jeder Frame eine manuelle Erstellung und die Integration in technische Zustände und Komponenten. Ein Ansatz, der die Geschichte in ein flexibles Framework integriert und auf wiederverwendbare Templates setzt, würde den Arbeitsaufwand deutlich reduzieren und die Erstellung zukünftiger Projekte erheblich vereinfachen.
Data-Driven Storytelling auf dem Prüfstand
Die Expert:innen, die den Prototyp für meine Masterarbeit evaluierten, betonten besonders die erhöhte Nutzerbindung und das gesteigerte Verständnis komplexer Themen durch diese neuen Erzählmethoden. Sie hoben hervor, dass die Personalisierung und Interaktivität die Nutzer:innen stärker in die Geschichte einbinden und ihnen ein tieferes Verständnis der präsentierten Daten ermöglichen.
Ich persönlich sehe besonders in der kontinuierlichen Weiterentwicklung von Technologien und Methoden großes Potenzial, um den Journalismus noch innovativer und nutzerzentrierter zu gestalten. Zukünftige Forschungen könnten sich darauf konzentrieren, die Benutzerfreundlichkeit weiter zu verbessern und die Integration solcher Systeme in den journalistischen Alltag zu erleichtern.
Marco hat nun das Förderprogramm für Abschlussarbeiten durchlaufen. Du hast auch ein spannendes Thema? Melde dich bei uns!


