Abschlussarbeiten im Media Lab | 25.10.2024
Daten für alle: Storytelling-gestützte Analyse von Nutzungsdaten
Online-Angebote großer Medienhäuser sammeln leicht haufenweise Nutzungsdaten an. Schwieriger ist es, die richtigen Schlussfolgerungen aus dieser Datenflut zu ziehen. Data Analytics ist dabei oft Expert:innen vorbehalten, obwohl auch weniger datenaffine Mitarbeiter:innen vom Blick in die Daten profitieren könnten. Mit Storytelling und generativer KI können Medienhäuser die Datenanalyse neu denken.
Online-Medien dauerhaft mit erfolgreichem Content zu bespielen, ist anspruchsvoll und erfordert, die Interessen der eigenen Userschaft gut zu verstehen. Präzise und schnelle Datenanalysen, zum Beispiel mit Hilfe von Datenvisualisierungen, können dabei helfen. Meist erschließen datenaffine Expert:innen die Daten und leiten Handlungsempfehlungen aus den Ergebnissen ab. Andere Mitarbeiter:innen im Medienhaus ohne Erfahrung in der Datenanalyse, etwa Journalist:innen oder Bildredakteur:innen, finden nur schwer Zugang. Dabei ist es auch für sie wertvoll, die Performance ihrer Inhalte bei der Userschaft besser zu verstehen. Ein vereinfachter Zugang würde die Datenzugänglichkeit und -kompetenz im Medienhaus fördern. Mich hat interessiert, wie eine Lösung für einen niedrigschwelligen Zugang zu Nutzungsdaten aussehen könnte. So entstand die Idee zu meiner Masterarbeit, die ich zusammen mit ZEIT ONLINE umgesetzt habe.
Storytelling mit Visual Analytics
Eine gute Strategie zur Vermittlung komplexer Daten ist Data-driven Storytelling: Datenanalysen und ihre Ergebnisse werden als Geschichte verpackt, meist in Kombination von Visualisierungen und Text. Der Ansatz findet bereits viel Anwendung im Datenjournalismus sowie in der Wissenschaftskommunikation - nicht aber in der visuellen Datenanalyse. Dabei sind die Vorteile des Storytellings auch bei Visual Analytics nützlich. Auf Grundlager der Nutzungsdaten von ZEIT ONLINE habe ich ausprobiert, ob sich Ergebnisse von Datenanalysen auch in Form von automatisch generierten Datenstorys durchführen lassen.
Ein Prototyp für Datengeschichten
Mein dafür generierter Prototyp bietet ein Suchinterface zur gesamten, tagesaktuellen Artikelsammlung von ZEIT ONLINE. Die Rohdaten sind so aufbereitet, dass auch nicht datenaffine Nutzer:innen sie erfassen können. Nach Eingabe eines bestimmten Artikels entsteht automatisiert eine Reihe von vier interaktiven Visualisierungen, die sich dann nach und nach erkunden lassen. Sie geben Informationen zur Performance eines Artikels, vergleichen den Text mit anderen thematisch ähnlichen, zeigen den zeitlichen Verlauf des Traffics und die Verteilung der User-Gruppen, die den Text gelesen haben.
Die Navigation basiert auf Buttons mit Fragen, denen Nutzer:innen durch einen Klick nachgehen können und die die dahinterliegende Visualisierung beantwortet. Zusätzlich erzeugt ein Large Language Model, ein LLM, basierend auf den Daten zum gewählten Artikel eine kurze textuelle Erklärung. Diese Erklärungen weisen auf die zentralen Erkenntnisse hin, die aus den Visualisierungen folgen. Sie helfen also dabei, die Anwendung zu lernen und die eigene Interpretation abzugleichen.
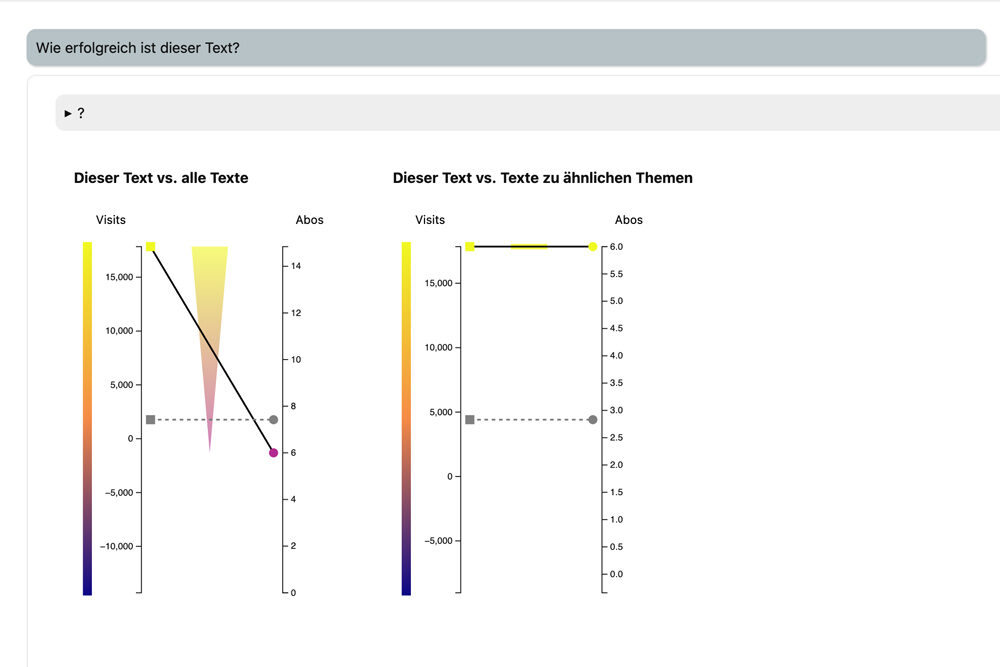
Das Ergebnis im Bild liefert folgende LLM-generierte Erklärung: „Der ausgewählte Text ist im Vergleich zu allen anderen Texten überdurchschnittlich beliebt in Bezug auf Besucherzahlen, zieht jedoch weniger Abonnements nach sich, da die Basis des Dreiecks die durchschnittliche Linie deutlich übersteigt, die Spitze jedoch darunter bleibt. Bei der Betrachtung im Kontext ähnlicher Texte liegt sowohl die Besucherzahl als auch die Anzahl der Abos des ausgewählten Textes über dem Durchschnitt, was auf eine erfolgreiche Performance in seinem Themencluster hinweist. Zwischen beiden Vergleichen besteht ein Unterschied in der relativen Leistung bezüglich der Abos, wobei im direkten Cluster-Vergleich eine stärkere Performance zu beobachten ist.“
Zusätzlich gibt es am Ende jeder Datenstory die Möglichkeit, mit Hilfe einer interaktiven Visualisierung über den gerade fokussierten Artikel hinaus in der gesamten Artikelsammlung zu forschen. So steuern User-Interessen die Analyse von der Ebene einzelner Texte zu ganzen Themenkomplexe.
Den Prototyp habe ich mit JavaScript und dem Frontend-Framework Svelte implementiert. Für die Visualisierungen habe ich die Library d3.js genutzt. Ein Node.js-Backend übernimmt das Bereitstellen und Vorverarbeiten der tagesaktuellen Daten aus dem BigQuery Data Warehouse.
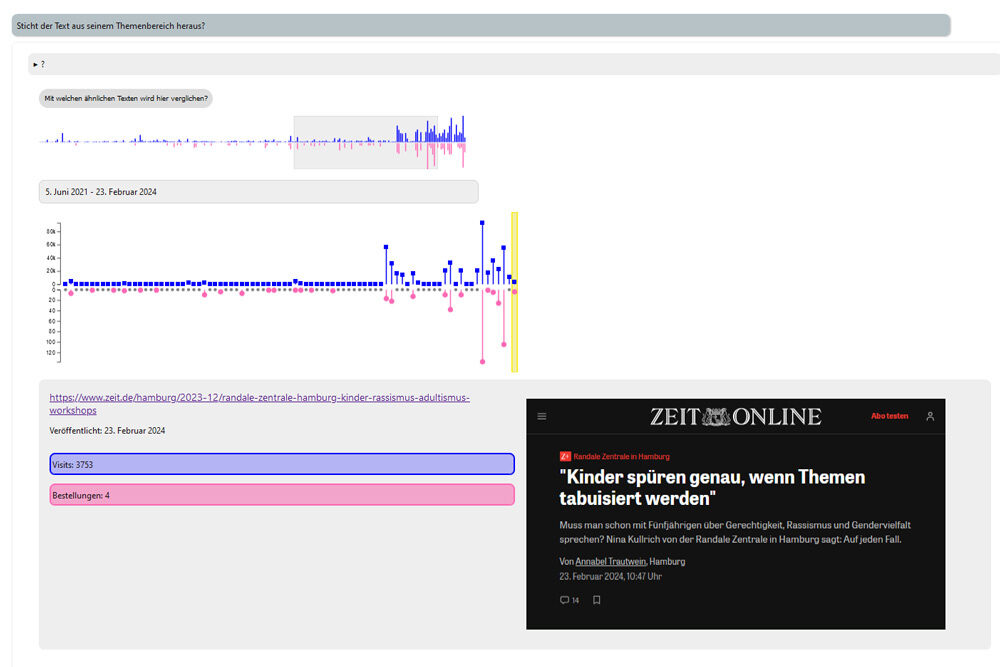
Usability-Test: Visual vs. Text
Um mehr über die Reaktion möglicher Nutzer:innen auf meinen Prototypen herauszufinden, habe ich ihn mit sechs Mitarbeitenden bei ZEIT ONLINE getestet. Meine Kolleg:innen waren dem Konzept der Storytelling-gestützten Analyse gegenüber sehr aufgeschlossen und mochten den interaktiven Charakter der Anwendung. Besonders interessant war für mich, wie unterschiedlich die einzelnen Testpersonen mit den dargestellten Informationen umgingen: Einige hatten einen sehr textuellen Fokus und zogen den meisten Nutzen aus den Erklärtexten, während andere auf rein visueller Ebene blieben und sich die Informationen viel lieber aus den Visualisierungen erschlossen.
Gerade für Testpersonen, die sonst selten auf eigene Faust Datenanalysen anstellen, war das geführte und lineare Konzept der Anwendung sehr hilfreich. Die sehr datenaffinen unter ihnen empfanden die Navigation jedoch als zu zeitaufwendig und vermissten die Übersichtlichkeit eines klassischen Dashboards. Trotzdem beschrieben einige von ihnen die Anwendung als inspirierend und einladend, sich tiefer mit den Daten auseinanderzusetzen.
Individualisierung bringt‘s
Das war eines meiner wichtigsten Learnings: die Unterschiede der Datenerschließung von Testperson zu Testperson. Data Analytics Anwendungen sollten deswegen möglichst viele Optionen anbieten, die Daten zu erforschen, und sich an den Kenntnisstand und die Präferenzen der jeweiligen Nutzer:in anpassen können. Eine Anwendung sollte zunächst einen möglichst niedrigschwelligen Zugang bieten, darauf basierend aber eine differenzierte, tiefe Erkundung der Daten ermöglichen. Storytelling und Visual Analytics zu verbinden hat sich als ein Balanceakt herausgestellt: zwischen nützlichen Orientierungshilfen im Datendschungel und analytischer Freiheit. Mein Storytelling-gestütztes Konzept bietet dafür eine gute Grundlage, kann aber natürlich noch verbessert werden. Die Testphase meiner Masterarbeit hat mir außerdem gezeigt, dass es sich lohnt, auf die Bedürfnisse weniger datenaffiner User:innen einzugehen, um Datenanalysen einem breiteren Publikum im Unternehmen zugänglich zu machen. Und das gilt sicher nicht nur für die Medienbranche.
Eva hat nun das Förderprogramm für Abschlussarbeiten durchlaufen. Du hast auch ein spannendes Thema? Melde dich bei uns!


